Présenter les agrégations sous forme de tableaux croisés
Les packages nécessaires
Nous allons avoir besoin de charger quelques packages pour réaliser notre tableau.
library(tidyverse)
library(flextable)
library(officer)
use_df_printer()Le sous jeu de données
Une agrégation d’un sous jeu de données issue de ggplot2::diamonds va être
utilisé pour définir le contenu du flextable.
Le code ci-dessous permet de filtrer certaines données afin que notre illustration ne contienne pas de nombreuses colonnes.
dat <- ggplot2::diamonds |>
filter(
cut %in% c("Good", "Very Good"),
clarity %in% c("I1", "SI1", "VS2")
) |>
mutate(price = price / 1000)
datcarat | cut | color | clarity | depth | table | price | x | y | z |
numeric | ordered | ordered | ordered | numeric | numeric | numeric | numeric | numeric | numeric |
0.3 | Very Good | H | SI1 | 61.9 | 55 | 0.3 | 4.1 | 4.1 | 2.5 |
0.3 | Good | J | SI1 | 64.0 | 55 | 0.3 | 4.2 | 4.3 | 2.7 |
0.3 | Good | J | SI1 | 63.4 | 54 | 0.4 | 4.2 | 4.3 | 2.7 |
0.3 | Good | J | SI1 | 63.8 | 56 | 0.4 | 4.2 | 4.3 | 2.7 |
0.3 | Very Good | J | SI1 | 62.7 | 59 | 0.4 | 4.2 | 4.3 | 2.7 |
0.2 | Very Good | E | VS2 | 63.8 | 55 | 0.4 | 3.9 | 3.9 | 2.5 |
0.3 | Very Good | J | SI1 | 59.4 | 62 | 0.4 | 4.4 | 4.4 | 2.6 |
0.3 | Very Good | J | SI1 | 58.1 | 62 | 0.4 | 4.4 | 4.5 | 2.6 |
0.3 | Very Good | J | VS2 | 62.2 | 57 | 0.4 | 4.3 | 4.3 | 2.7 |
0.2 | Very Good | D | VS2 | 60.5 | 61 | 0.4 | 4.0 | 4.0 | 2.4 |
n: 8549 | |||||||||
L’agrégation principale
Maintenant, agrégeons l’ensemble de données filtrées et
comptons les observations. Le tableau de données créé aura
trois dimensions, cut, color et clarity, qui seront
utilisées comme lignes ou colonnes dans le flextable final.
summary_dat <- dat |>
group_by(cut, color, clarity) |>
summarise(
y_mean = mean(price, na.rm = TRUE),
y_sd = sd(price, na.rm = TRUE),
.groups = "drop"
)
summary_datcut | color | clarity | y_mean | y_sd |
ordered | ordered | ordered | numeric | numeric |
Good | D | I1 | 3.5 | 2.2 |
Good | D | SI1 | 3.0 | 2.8 |
Good | D | VS2 | 3.6 | 3.4 |
Good | E | I1 | 4.4 | 2.5 |
Good | E | SI1 | 3.2 | 3.1 |
Good | E | VS2 | 3.8 | 3.3 |
Good | F | I1 | 2.6 | 1.9 |
Good | F | SI1 | 3.3 | 3.0 |
Good | F | VS2 | 3.8 | 3.2 |
Good | G | I1 | 3.2 | 2.0 |
n: 42 | ||||
Les autres agrégations
Les comptages suivants seront utilisés pour montrer les comptages dans les lignes.
cut_counts <- count(dat, cut, name = "n_cut")
cut_countscut | n_cut |
ordered | integer |
Good | 2,634 |
Very Good | 5,915 |
Les comptages suivants seront utilisés pour montrer les comptages dans les colonnes.
clarity_counts <- count(dat, clarity, name = "n_clarity")
clarity_countsclarity | n_clarity |
ordered | integer |
I1 | 180 |
SI1 | 4,800 |
VS2 | 3,569 |
Les valeurs de formattage par défaut
Cette étape n’est pas obligatoire, elle définit certaines valeurs par défaut pour les flextables qui seront produit ultérieurement.
init_flextable_defaults()
set_flextable_defaults(
theme_fun = theme_booktabs,
big.mark = " ", font.color = "#333333",
border.color = "#333333",
padding = 3,
)Utilisation de la fonction tabulator
Maintenant que tous les jeux de données sont prêts à être utilisés,
appelons la fonction tabulator() qui va préparer un objet qui sera envoyé à as_flextable().
ftd <- fp_text_default(color = "#f24f26")
# create tabulator object to be used with `as_flextable()` ----
tab <- tabulator(
x = summary_dat,
rows = c("cut", "color"),
columns = "clarity",
hidden_data = cut_counts,
row_compose = list(
cut = as_paragraph(cut, as_chunk(x = paste0("\nn = ", n_cut), props = ftd))
),
# defines the only cells to show in the result
`y stats` = as_paragraph(y_mean, " (\u00B1 ", y_sd, ")")
)
## get colkeys corresponding to multiple "y stats" ----
colkeys <- tabulator_colnames(tab, columns = "y stats")
colkeys
## [1] "I1@y stats" "SI1@y stats" "VS2@y stats"Le flextable
Un flextable peut facilement être produit avec le code suivant:
ft <- as_flextable(tab, separate_with = "cut")
ftcut | color | I1 | SI1 | VS2 | |||
Good | D | 3.5 (± 2.2) | 3.0 (± 2.8) | 3.6 (± 3.4) | |||
E | 4.4 (± 2.5) | 3.2 (± 3.1) | 3.8 (± 3.3) | ||||
F | 2.6 (± 1.9) | 3.3 (± 3.0) | 3.8 (± 3.2) | ||||
G | 3.2 (± 2.0) | 4.1 (± 3.9) | 4.1 (± 3.3) | ||||
H | 3.8 (± 2.2) | 4.2 (± 3.8) | 4.4 (± 4.2) | ||||
I | 4.2 (± 2.9) | 4.7 (± 4.5) | 6.0 (± 5.1) | ||||
J | 3.8 (± 2.1) | 4.6 (± 3.9) | 4.8 (± 3.6) | ||||
Very Good | D | 2.6 (± 0.8) | 3.2 (± 2.9) | 3.1 (± 3.3) | |||
E | 3.4 (± 2.2) | 3.2 (± 3.1) | 3.3 (± 3.5) | ||||
F | 4.3 (± 2.6) | 3.6 (± 3.2) | 4.0 (± 3.8) | ||||
G | 3.2 (± 2.1) | 3.5 (± 3.6) | 4.4 (± 4.0) | ||||
H | 5.3 (± 2.5) | 4.9 (± 4.4) | 4.6 (± 4.0) | ||||
I | 6.0 (± 4.9) | 5.2 (± 4.5) | 5.8 (± 5.1) | ||||
J | 4.5 (± 2.7) | 5.0 (± 4.1) | 5.3 (± 4.5) |
Personnalisation du tableau
Il faut que nous ajoutions les comptages dans les colonnes.
ft <- append_chunks(ft,
j = colkeys, i = 1, part = "header",
as_paragraph(
"\n",
as_chunk(x = paste0("(n = ", clarity_counts$n_clarity, ")"), props = ftd)
)
)
ftcut | color | I1 | SI1 | VS2 | |||
Good | D | 3.5 (± 2.2) | 3.0 (± 2.8) | 3.6 (± 3.4) | |||
E | 4.4 (± 2.5) | 3.2 (± 3.1) | 3.8 (± 3.3) | ||||
F | 2.6 (± 1.9) | 3.3 (± 3.0) | 3.8 (± 3.2) | ||||
G | 3.2 (± 2.0) | 4.1 (± 3.9) | 4.1 (± 3.3) | ||||
H | 3.8 (± 2.2) | 4.2 (± 3.8) | 4.4 (± 4.2) | ||||
I | 4.2 (± 2.9) | 4.7 (± 4.5) | 6.0 (± 5.1) | ||||
J | 3.8 (± 2.1) | 4.6 (± 3.9) | 4.8 (± 3.6) | ||||
Very Good | D | 2.6 (± 0.8) | 3.2 (± 2.9) | 3.1 (± 3.3) | |||
E | 3.4 (± 2.2) | 3.2 (± 3.1) | 3.3 (± 3.5) | ||||
F | 4.3 (± 2.6) | 3.6 (± 3.2) | 4.0 (± 3.8) | ||||
G | 3.2 (± 2.1) | 3.5 (± 3.6) | 4.4 (± 4.0) | ||||
H | 5.3 (± 2.5) | 4.9 (± 4.4) | 4.6 (± 4.0) | ||||
I | 6.0 (± 4.9) | 5.2 (± 4.5) | 5.8 (± 5.1) | ||||
J | 4.5 (± 2.7) | 5.0 (± 4.1) | 5.3 (± 4.5) |
Ajoutons un titre :
ft <- add_header_lines(ft, "Subset of original dataset")
ftSubset of original dataset | |||||||
cut | color | I1 | SI1 | VS2 | |||
Good | D | 3.5 (± 2.2) | 3.0 (± 2.8) | 3.6 (± 3.4) | |||
E | 4.4 (± 2.5) | 3.2 (± 3.1) | 3.8 (± 3.3) | ||||
F | 2.6 (± 1.9) | 3.3 (± 3.0) | 3.8 (± 3.2) | ||||
G | 3.2 (± 2.0) | 4.1 (± 3.9) | 4.1 (± 3.3) | ||||
H | 3.8 (± 2.2) | 4.2 (± 3.8) | 4.4 (± 4.2) | ||||
I | 4.2 (± 2.9) | 4.7 (± 4.5) | 6.0 (± 5.1) | ||||
J | 3.8 (± 2.1) | 4.6 (± 3.9) | 4.8 (± 3.6) | ||||
Very Good | D | 2.6 (± 0.8) | 3.2 (± 2.9) | 3.1 (± 3.3) | |||
E | 3.4 (± 2.2) | 3.2 (± 3.1) | 3.3 (± 3.5) | ||||
F | 4.3 (± 2.6) | 3.6 (± 3.2) | 4.0 (± 3.8) | ||||
G | 3.2 (± 2.1) | 3.5 (± 3.6) | 4.4 (± 4.0) | ||||
H | 5.3 (± 2.5) | 4.9 (± 4.4) | 4.6 (± 4.0) | ||||
I | 6.0 (± 4.9) | 5.2 (± 4.5) | 5.8 (± 5.1) | ||||
J | 4.5 (± 2.7) | 5.0 (± 4.1) | 5.3 (± 4.5) | ||||
Et ajoutez une ligne spéciale pour que, lors du rendu en Word, le haut du flextable indique le numéro de page correspondant à sa position dans le document.
ft <- add_header_lines(ft, "Page N°") |>
append_chunks(i = 1, part = "header", j = 1,
as_word_field(x = "Page")) |>
align(part = "header", align = "right", i = 1) |>
set_caption(caption = "Prices of over 50 000 round cut diamonds")
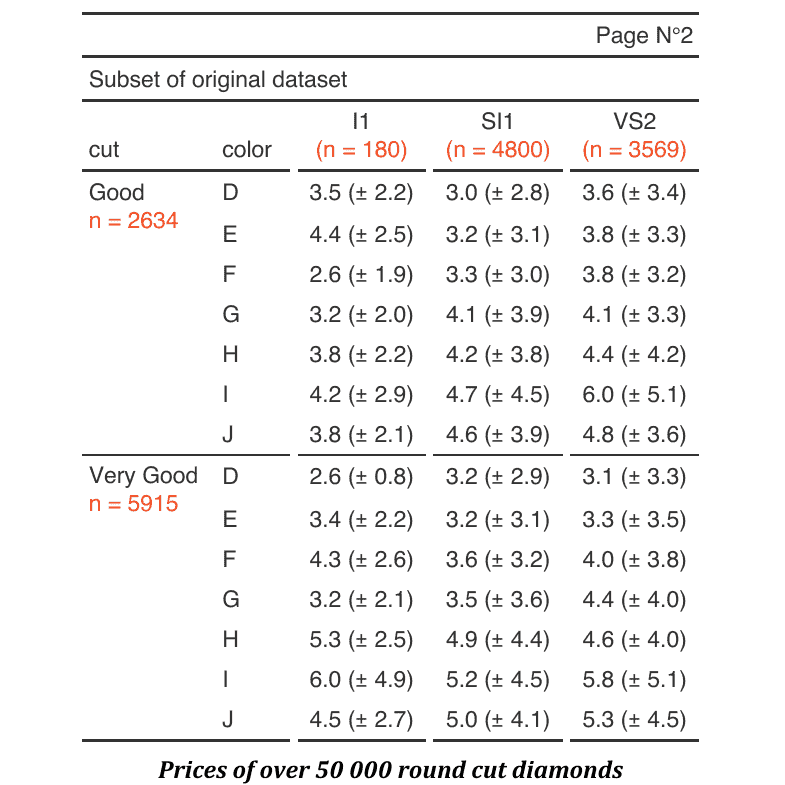
ftPage N°NA | |||||||
Subset of original dataset | |||||||
cut | color | I1 | SI1 | VS2 | |||
Good | D | 3.5 (± 2.2) | 3.0 (± 2.8) | 3.6 (± 3.4) | |||
E | 4.4 (± 2.5) | 3.2 (± 3.1) | 3.8 (± 3.3) | ||||
F | 2.6 (± 1.9) | 3.3 (± 3.0) | 3.8 (± 3.2) | ||||
G | 3.2 (± 2.0) | 4.1 (± 3.9) | 4.1 (± 3.3) | ||||
H | 3.8 (± 2.2) | 4.2 (± 3.8) | 4.4 (± 4.2) | ||||
I | 4.2 (± 2.9) | 4.7 (± 4.5) | 6.0 (± 5.1) | ||||
J | 3.8 (± 2.1) | 4.6 (± 3.9) | 4.8 (± 3.6) | ||||
Very Good | D | 2.6 (± 0.8) | 3.2 (± 2.9) | 3.1 (± 3.3) | |||
E | 3.4 (± 2.2) | 3.2 (± 3.1) | 3.3 (± 3.5) | ||||
F | 4.3 (± 2.6) | 3.6 (± 3.2) | 4.0 (± 3.8) | ||||
G | 3.2 (± 2.1) | 3.5 (± 3.6) | 4.4 (± 4.0) | ||||
H | 5.3 (± 2.5) | 4.9 (± 4.4) | 4.6 (± 4.0) | ||||
I | 6.0 (± 4.9) | 5.2 (± 4.5) | 5.8 (± 5.1) | ||||
J | 4.5 (± 2.7) | 5.0 (± 4.1) | 5.3 (± 4.5) | ||||
Rendu avec Word
Le code suivant produit un document Word avec le package ‘officer’, le contenu est un faux contenu. Le but est de montrer comment notre flextable est rendu dans un document Word.
psum_txt <- "Lorem ipsum dolor sit amet, purus ut nullam nisl vehicula non ligula sem non. Egestas nascetur, eu sed nec mattis semper arcu auctor sagittis id consequat non? Facilisi vestibulum ac nec primis. Posuere sociis ligula tempor, mattis sed sed dapibus. Taciti nulla mattis aliquet dictumst, nisi aenean, pulvinar! Hendrerit porttitor quis praesent mi nisl lorem mauris ut nulla. Tincidunt in sit sit quisque id molestie. Eros, orci ligula phasellus sed erat vel vivamus penatibus aliquam, scelerisque turpis sociis erat."
landscape_two_columns <- block_section(
prop_section(
type = "continuous",
section_columns = section_columns(widths = c(3, 3))
)
)
read_docx(path = "template.docx") |>
body_add_par(value = "Lorem ipsum", style = "heading 1") |>
body_add_par(psum_txt) |>
body_add_par(value = "Tempor velit sed", style = "heading 2") |>
body_end_block_section(value = block_section(property = prop_section(type = "continuous"))) |>
body_add_par(psum_txt) |>
body_add_par(psum_txt) |>
body_end_block_section(value = landscape_two_columns) |>
body_add_par(psum_txt) |>
body_add_par(psum_txt) |>
body_add_break() |>
body_add_par(value = "Mattis potenti metus", style = "heading 2") |>
body_add_par(value = "") |>
body_add_flextable(value = ft, topcaption = FALSE, keepnext = FALSE) |>
body_add_par(psum_txt) |>
print(target = "illustration.docx")Vous pouvez télécharger le document Word: illustration.docx
Après avoir mis à jour les champs dans le document, il a ce rendu :

illustration